# Platforms
# Prerequisites for the development: git(hub) user's guide
As a developer, you first have to sign up to Github (opens new window) to be able to contribute to ezPAARSE and:
- write a new parser
- maintain an existing parser
- contribute to improvements in the core of ezPAARSE's code
You then need to know a few git (opens new window) commands:
#get a local version of the github
git clone https://github.com/ezpaarse-project/ezpaarse.git
#if you already had the project, update it
cd ezpaarse/
git pull
#edit a file
cd ezpaarse/
echo "// my modification" >> ./app.js
#get an overview of which files have been modified/added/deleted (before a commit)
git status
#compare the local modifications with the local repository, line by line, before saving the modifications
git diff
#send the modifications to you local repository
git commit ./app.js -m "a comment explaining my modification""
#display the list of commits
git log
#add a new file
touch ./myexamplefile
git add ./myexamplefile
git commit ./myexamplefile -m "add an example file"
#send the (commmitted) modifications to the distant repository (authorization from the distant repo needed).
git push
Note: unless you have a privileged access (from the ezPAARSE team), you must first "fork" the ezPAARSE github repository in order to work on that copy. Once you are satisfied with your changes, you can submit your work to the team by sending a "pull request" (opens new window). Your job will be reviewed and integrated by the team, if no problem is detected. The team then provides write access rights to regular contributors, in order to facilitate contributions.
# How does a parser work?
A parser takes the form of an executable parser.js file accompanied by a description file manifest.json (opens new window) and a validation structure (contained in the test directory, see below).
The executable can take two kinds of input:
- a stream of URLs to analyze (one per line)
- or stream of JSON objects (one per line) with the
--jsonoption, each containing:- the
urlto analyze - other information to qualify the access event (such as the size of the download)
- the
The parser outputs a stream of JSON objects, one per line and for each analyzed URL. The object may be empty if the parser doesn't find anything.
Its usage is documented when you call it with the --help option.
An example parser (opens new window) is available.
# Usage Examples
echo "http://www.sciencedirect.com:80/science/bookseries/00652296" | ./parser.js
#{"unitid":"00652296","print_identifier":"0065-2296","title_id":"00652296","rtype":"BOOKSERIE","mime":"MISC"}
echo '{ "url": "http://www.sciencedirect.com:80/science/bookseries/00652296", "status": 200 }' | ./parser.js --json
#{"unitid":"00652296","print_identifier":"0065-2296","title_id":"00652296","rtype":"BOOKSERIE","mime":"MISC"}
# Writing a Parser
Parsers are written in Javascript. A good knowledge of the language is not really necessary to write a parser. Most of the code being outsourced in a common file for all parsers, only the URL analysis function must be adapted, making the code short and relatively simple. Most parsers still require a basic knowledge of regular expressions.
Writing a new parser thus consists of:
- creating the manifest.json file (see below)
- creating the test file, according to what is documented on the plaftform analysis page
- creating the parser so that its output is conform to the test file (see below)
- launch the validation tests (see below)
Once the parser passes the tests, it can be integrated into the github repo.
You can either work from the platforms directory in an ezPAARSE instance, or clone the ezpaarse-platforms (opens new window) repository.
A skeleton (opens new window) can be used as a starting point. The directory structure and base files can be automatically generated by executing make init from the root directory of the platforms (you may need to launch make install before).
Some tools are available online to help you in the the writing of regular expressions (opens new window).
# Testing Parsers
Each parser comes with the necessary to be tested: one or more files located in the test subdirectory. These files are in CSV format and follow the platform.version.csv pattern.
The test principle is represented by the following diagram:
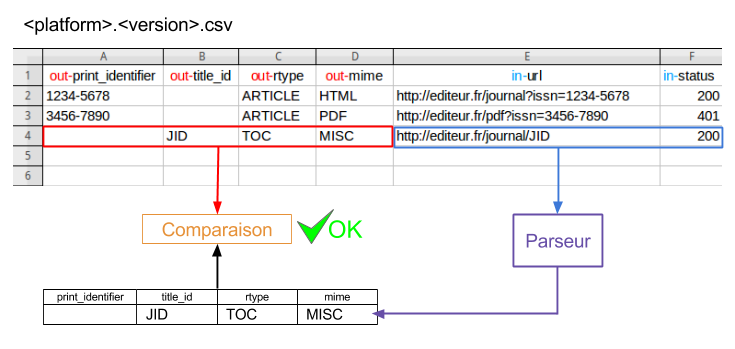
For each row, values from columns prefixed with in- are sent to the parser, and the result is compared with the values coming from columns prefixed with out-. These must be strictly identical.
More details about the identifiers returned by the parsers are available on this page.
When the parser only takes an input URL (ie. no other fields prefixed with in-), it is possible to manually run the test file with the following command (from the directory the platform):
#platform.version.csv is the test file
cat test/platform.version.csv | ../../bin/csvextractor --fields="in-url" -c --noheader | ./parser.js
The tests are now integrated into ezPAARSE's platforms folder (instead of coming with the core of ezPAARSE). It means that ezPAARSE doesn't need to be running, as the parsers' tests are now independent. Before you launch the platforms' tests, you need to setup the environment:
cd platforms/
make install
Then you can either test all parsers:
make test
or test only a selection, by naming them (use the shortnames). For example, if you want to test the parsers for Nature and ScienceDirect:
make test sd npg
See the ezpaarse-platforms README (opens new window) for more information.
# Description of a parser
The parser is described by a manifest.json file, located in its root directory.
This file contains the following information:
- name (mandatory): the short name of the parser, matching the name of its directory. Care should be taken not to use a name already used.
- longname (mandatory): the long name of the parser, used in the documentation.
- domains (mandatory): an array of domains that the parser should handle.
- publisher_name: if the parser covers resources of a single publisher, you can put its name in this field.
- describe: a longer description for the parser, can be a paragraph.
- version: the current version of the parser.
- status: the current status of the parser (
betaorstable). - contact: main contributor(s) of the parser.
- docurl: the URL of the documentation on the Analogist website.
- pkb-domains: if the platform has a PKB with a column that contains domains, you can enter the name of the column in this field so that the parser handles those domains.
# Vendors' PKBs management principles
Knowledge bases are used to:
- match the identifiers found on publishers platforms (which can be specific and proprietary) and standardized identifiers (like ISSNs)
- include the titles of accessed resources in the results
Knowledge bases are saved as text file KBART format (opens new window) and are specific to each platform.
The platform_AllTitles.txt file contains the mappings between identifiers of a specific platform and ISSN (or other standardized identifier). The KBART field called title_id is used to establish this correspondence with the print_identifier field (for paper resources) or online_identifier (electronic resources). The list of KBART fields (opens new window) and their meaning is available.
Knowledge bases are loaded by ezPAARSE and their structure must be previously controlled by the pkbvalidator tool